
この記事は note に公開した【業界の主流に逆らう】月 10,000 件の分析自動化 AI エージェントを 1 年運用してわかった、セマンティックレイヤーが要らない理由を、ブログ用に整形して再掲したものです。
前回の note で、AI Ready なデータ基盤は 2 軸(ベーステーブル群 + コンテキスト&ハーネスエンジニアリング)+ ガードレールで構成される、という話を書きました。
【500 名規模で 1 年運用】AI 分析エージェントを 1 年運用して見えた、AI Ready なデータ基盤の正体
この記事を読んでくれた人から、いくつか同じ質問をもらいました。
「セマンティックレイヤー(Semantic Layer)の話が一切出てこなかったのはなぜ?業界では Snowflake も dbt も Databricks も、AI には Semantic Layer が必須だと言ってるけど」
確かに。業界の主流は「分析自動化 AI エージェントには Semantic Layer が必要」です。Snowflake Cortex Analyst も、dbt MetricFlow も、Databricks Genie も、AtScale も、その前提で売り込んでいます。
でも、僕は前回の記事でわざと触れませんでした。
理由はシンプルで、500 名 / 月 10,000 件の分析自動化 AI エージェント運用において、Semantic Layer は本質的な答えにはならなかったからです。
この記事では、その理由を 3 つ書きます。ただし重要な但し書きもあって、会社の規模・データの量・分析の深さによって、答えは反転します。そこも合わせて整理します。
まず、Semantic Layer とは何か
業界用語に詳しくない人向けに、軽く定義から。
Semantic Layer とは、生データの上に乗せる「業務の言葉」と「数値の計算式」をひも付けた抽象レイヤーのことです。
- 「LTV」というメトリクスは、こういう SQL で計算する
- 「アクティブユーザー」はこういう条件で抽出する
- これらは「日次・週次・月次」の粒度で、「チャネル別・セグメント別」に集計できる
——みたいな定義を 1 箇所に書いておく仕組み。代表的な実装は dbt MetricFlow / Cube / AtScale / Snowflake Cortex Semantic Model / LookML など。
業務質問が来ると、Semantic Layer は「定義済みのメトリクスとディメンションの組み合わせ」として翻訳して、内部で SQL を組み立てます。
聞こえはいい。実際、整ったスキーマで dbt 公式が出した 2026 年ベンチマークでは:
- Semantic Layer:精度 98.2%
- Text-to-SQL(自由 SQL 生成):精度 90.0%
dbt: Semantic Layer vs. Text-to-SQL: 2026 Benchmark Update
数字だけ見れば、Semantic Layer の圧勝に見える。
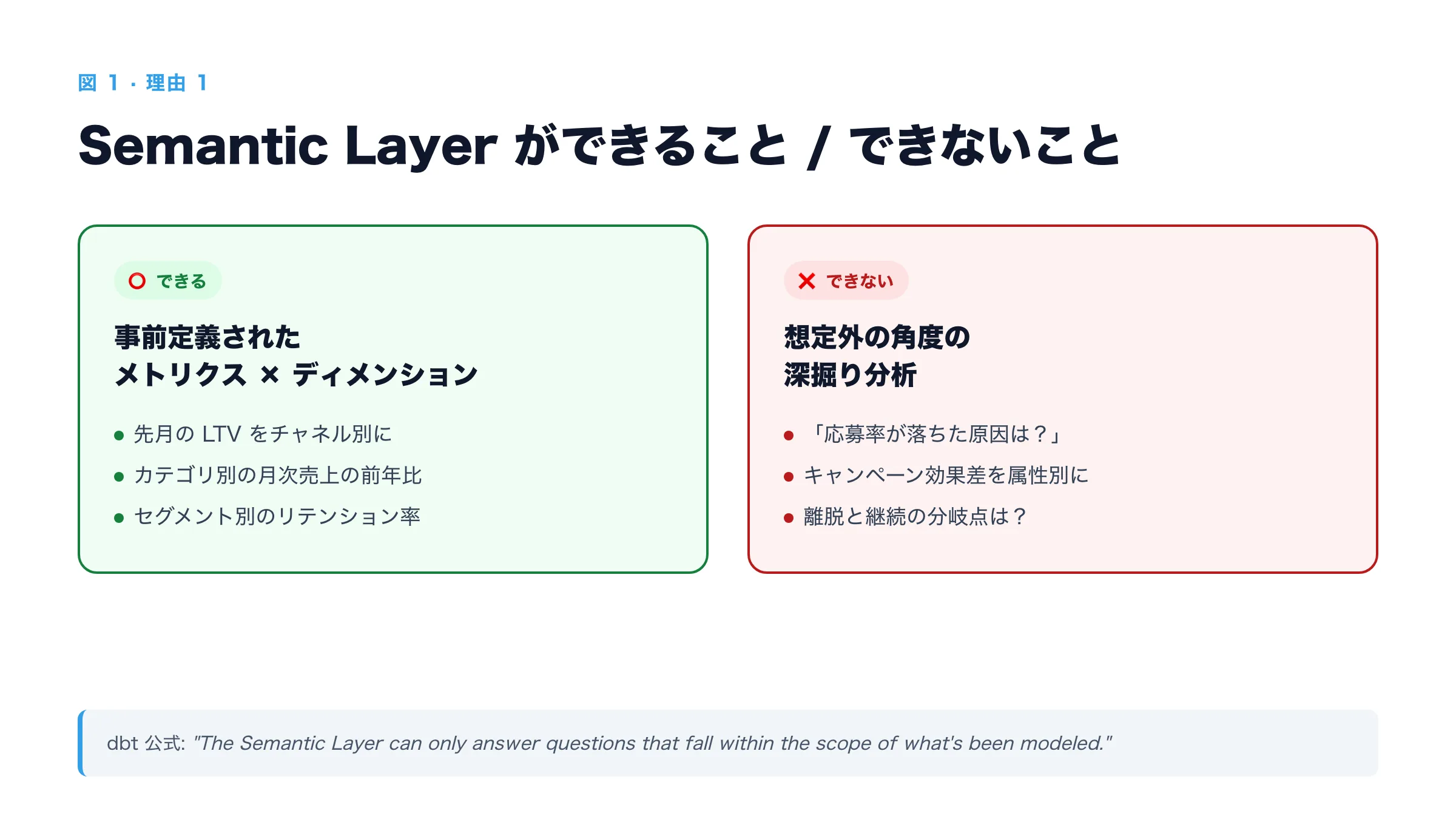
理由 1:表層的な分析しかできない
これは Semantic Layer の構造的な限界です。
Semantic Layer が扱えるのは「事前に定義したメトリクスとディメンションの組み合わせ」だけ。これは dbt 公式自身も認めていて、
"The Semantic Layer can only answer questions that fall within the scope of what's been modeled."
つまり、こういう質問には強いです:
- 「先月の LTV をチャネル別に出して」
- 「カテゴリ別の月次売上の前年比」
- 「セグメント別のリテンション率」
定義済みのパターンに沿って組み合わせれば答えが出る。ところが、500 名運用の現場で実際に飛んでくる質問は、こういう形でした。
- 「先月応募率が落ちた原因は?特定セグメントに偏ってる?それとも全体?」
- 「キャンペーン A と B の効果差を、属性ごとに detailed に見せて、有意差も判定して」
- 「離脱した顧客と継続した顧客を比較して、どの行動パターンが分岐点になってる?」
これらは事前定義されたメトリクスの組み合わせでは答えが出ない。新しい角度の集計、複数テーブルの動的な JOIN、仮説検証のための条件分岐、これらが必要になる。
dbt 公式も、ad-hoc / 深掘り分析については「Semantic Layer で答えが出ないなら Text-to-SQL に fallback しろ」と書いている。つまり、Semantic Layer は「想定された質問に対する精度」は高いが、「想定外の質問に対する深掘り」は構造的にできない。
経営会議で分析自動化 AI エージェントが本当に欲しい瞬間は、後者の方なんです。「事前に想定された質問」しか答えられない AI は、結局ダッシュボードと同じで、見るだけになる。
理由 2:Semantic Layer の情報量だけでは、分析自動化 AI エージェントには足りない
これは業界内でも徐々に認識されてきている話です。Tellius の記事から引用:
"While organizations built semantic layers for queries, an agent-ready semantic layer must go beyond query governance to provide persistent business context, domain-specific knowledge, investigation planning rules, and orchestration logic."
Tellius: Why Your Semantic Layer Isn't Ready for AI Agents
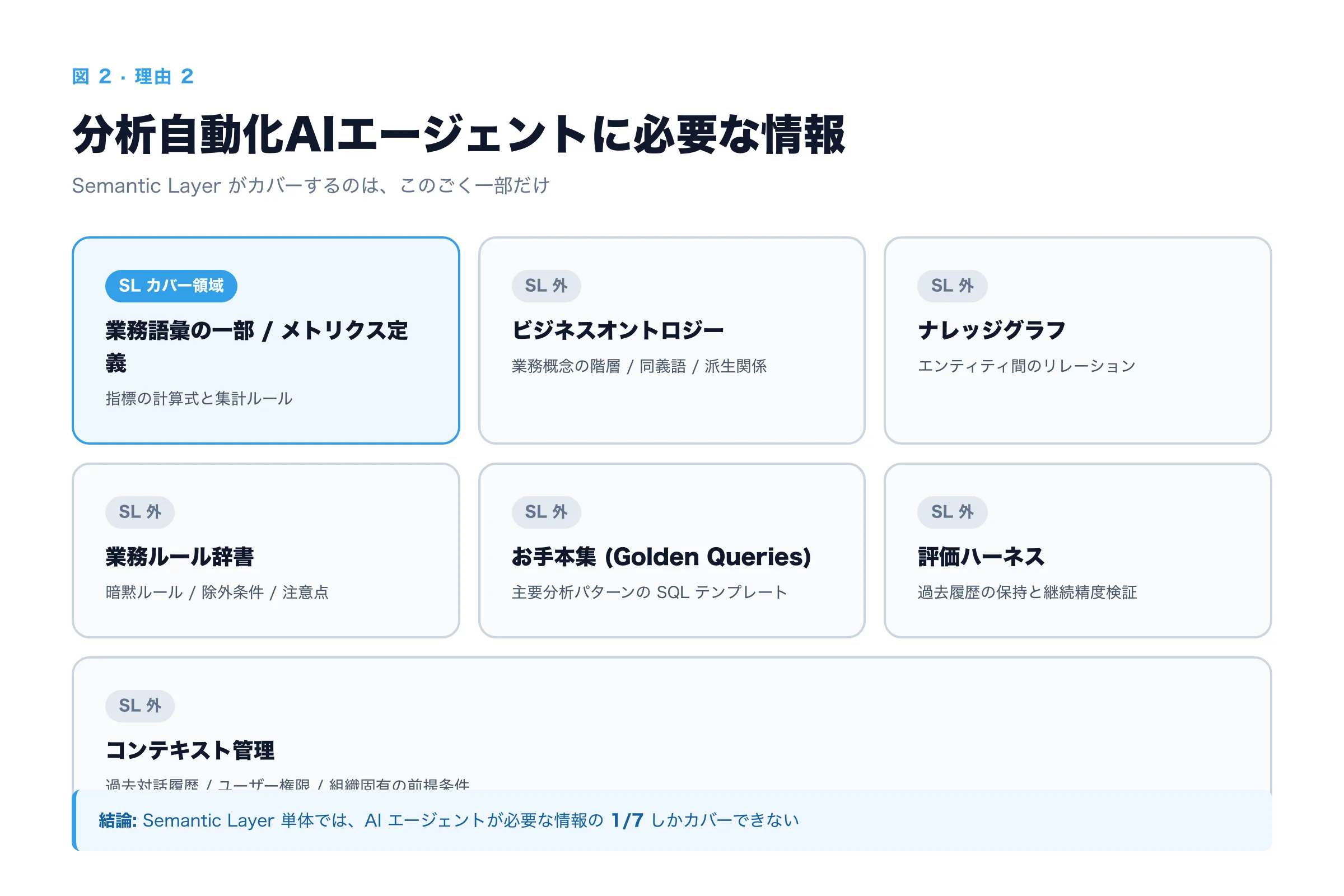
つまり、従来の Semantic Layer が持っているのは「メトリクス定義 + ディメンション + 集計ルール」だけ。でも分析自動化 AI エージェントが必要なのは、前回 note で書いた「軸 2:コンテキスト&ハーネスエンジニアリング」の中身:
- ビジネスオントロジー — 業務概念の階層、同義語、派生関係
- ナレッジグラフ — エンティティ間のリレーションをグラフ構造で
- 業務ルール辞書 — 暗黙ルール、除外条件、注意点
- お手本集(Golden Queries) — 主要分析パターンの SQL テンプレート
- 評価ハーネス — 過去の質問・SQL・回答の履歴と継続検証
- コンテキスト管理 — 過去の対話履歴、ユーザーごとの権限、組織固有の前提
Semantic Layer がカバーするのは、このうち「業務語彙の一部」と「メトリクス定義」だけ。ビジネスオントロジーやナレッジグラフ、業務ルール辞書、お手本集、評価ハーネスは、Semantic Layer の外で別に整える必要があります。
つまり、Semantic Layer は分析自動化 AI エージェントが必要とする情報量の、ごく一部しか提供していない。これだけでは、AI が業務文脈に踏み込んだ深掘り分析を組み立てるには足りない、というのが実体験からの結論です。
理由 3:AI Ready なデータ基盤があれば、Text-to-SQL でも Semantic Layer 同等の精度は保てる
Semantic Layer が「精度のために必要」と語られる背景には、Text-to-SQL の精度が低いという前提があります。
確かに、生データに対していきなり LLM に SQL を書かせると、精度はかなり落ちます。ただ、これは「業務語彙が外在化されていない、お手本もない、データ粒度がバラバラ」な状態での話。前回 note で書いた AI Ready なデータ基盤(2 軸 + ガードレール)を整えた状態では、状況が変わります。
- ベーステーブルが業務粒度で整っている
- 業務語彙が辞書化されている(「LTV」「応募率」の定義 + オーナー)
- 暗黙ルールが構造化記述されている(「特定キャンペーンは除外」など)
- お手本集(Golden Queries)が登録されている
この状態で Text-to-SQL を回すと、Semantic Layer 同等の精度は保てます。低信頼度の回答にはガードレール(信頼度スコア + SQL 引用 + 計算前提引用)を付ければ、ユーザー側で判断できる。
つまり、AI Ready なデータ基盤が前提なら、Text-to-SQL の精度問題はかなり解決する。Semantic Layer は「精度のために必須」ではなくなる。
ただし、データ量・種類が少ない会社では話が変わる
ここまで「Semantic Layer は不要」という話をしてきましたが、これは前提条件付きです。500 名 / 月 10,000 件 / 多様なデータソースという前提での話。
データの量と種類が少ない会社、たとえば:
- 数十名規模、扱うデータソースが業務システム + 顧客管理 + 主要マーケチャネル の数種類程度
- 質問のパターンも「先月の主要 KPI」「セグメント別の推移」など定型的
- 深掘り分析を必要とする頻度が低い(または分析専任がいるので、深掘りは人がやる)
こういう会社では、フル AI Ready 化(軸 1 のベーステーブル整備 + 軸 2 のコンテキスト&ハーネス)まで作り込む必要は、正直ありません。raw データ + Semantic Layer + LLM の構成で、業務質問の 8 割には十分に答えられます。
dbt 公式も、enterprise(大規模・複雑)には Semantic Layer、ad-hoc / 小規模には Text-to-SQL、という使い分けを推奨しています。小規模の場合、無理に AI Ready 化のフルセットを作るより、Semantic Layer から始める方が現実的なケースは多い。

ただし、深掘り分析を諦めることになる
ここで気をつけたいのは、Semantic Layer ベースで運用すると、「事前定義の範囲を超える質問は出てこなくなる」という現象が起きやすいことです。
ユーザー側も、回答が返ってこない質問は、徐々に投げなくなる。結果として、組織として「深掘り分析の文化」が育たない可能性があります。
事業が小さいうちは、それでも経営判断は回ります。でも事業が成長して、競合との差別化が「データドリブンな深掘り意思決定」に依存し始めたとき、Semantic Layer ベースのままでは追いつかなくなる。そこから AI Ready なデータ基盤に作り変えるのは、量を分解して再構築するコストが大きい。
つまり、長期的には AI Ready なデータ基盤(軸 1 + 軸 2)に向かうのが筋。最初の入り口として Semantic Layer から始めるのは合理的だが、それで終わりではない。
まとめ
業界の主流は「分析自動化 AI エージェントには Semantic Layer が必要」だが、月 10,000 件規模で 1 年運用してきた現場感では、Semantic Layer は本質的な答えにならなかった。理由は 3 つ。事前定義の範囲しか扱えず深掘り分析ができない。AI 分析エージェントが必要とする情報(ビジネスオントロジー / ナレッジグラフ / 業務ルール辞書 / お手本集 / 評価ハーネス)の一部しか提供できない。AI Ready なデータ基盤を整えれば Text-to-SQL でも同等精度を保てるため、わざわざ Semantic Layer を経由する必要がない。
ただし、データの量と種類が少ない会社では話が変わり、raw + Semantic Layer + LLM で 8 割の質問には答えられる。事業成長と共に深掘り分析の天井に当たるので、いずれは AI Ready なデータ基盤への移行を視野に入れる必要があるが、入り口としては合理的な選択肢になる。
「Semantic Layer を入れたから AI Ready」ではない、というのが本記事の主張。