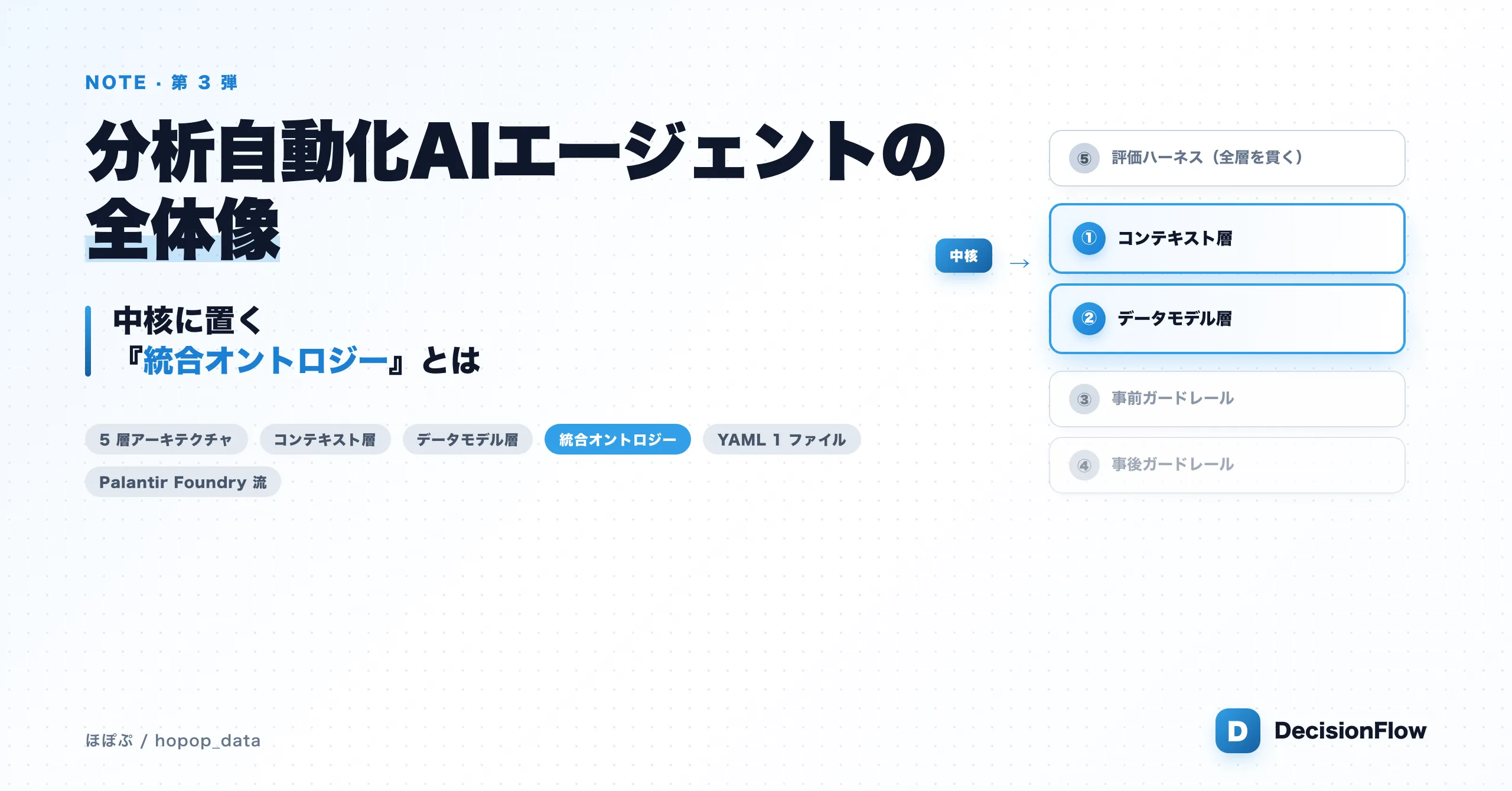
この記事は note に公開した分析自動化AIエージェントの全体像 — 中核に置く『統合オントロジー』とはを、ブログ用に整形して再掲したものです。
前回の note を予想以上に多くの方に読んでいただきました。そして「Semantic Layer 不要」というメッセージが想像以上に独り歩きして、補足が必要な反応もいくつか見えました。
【業界の主流に逆らう】月 10,000 件の分析自動化 AI エージェントを 1 年運用してわかった、セマンティックレイヤーが要らない理由
「Semantic Layer 不要」は 第 1 弾で書いた 2 軸が揃っている前提での話です。ここの誤解を解くために、今回は 分析自動化AIエージェントの全体像を 1 つの図にまとめ直す ことから始めます。
【500 名規模で 1 年運用】AI 分析エージェントを 1 年運用して見えた、AI Ready なデータ基盤の正体
その上で、その中の核となる 統合オントロジー を解説します。これがあれば、Semantic Layer はいらない。
分析自動化AIエージェントの全体像 — 5 層
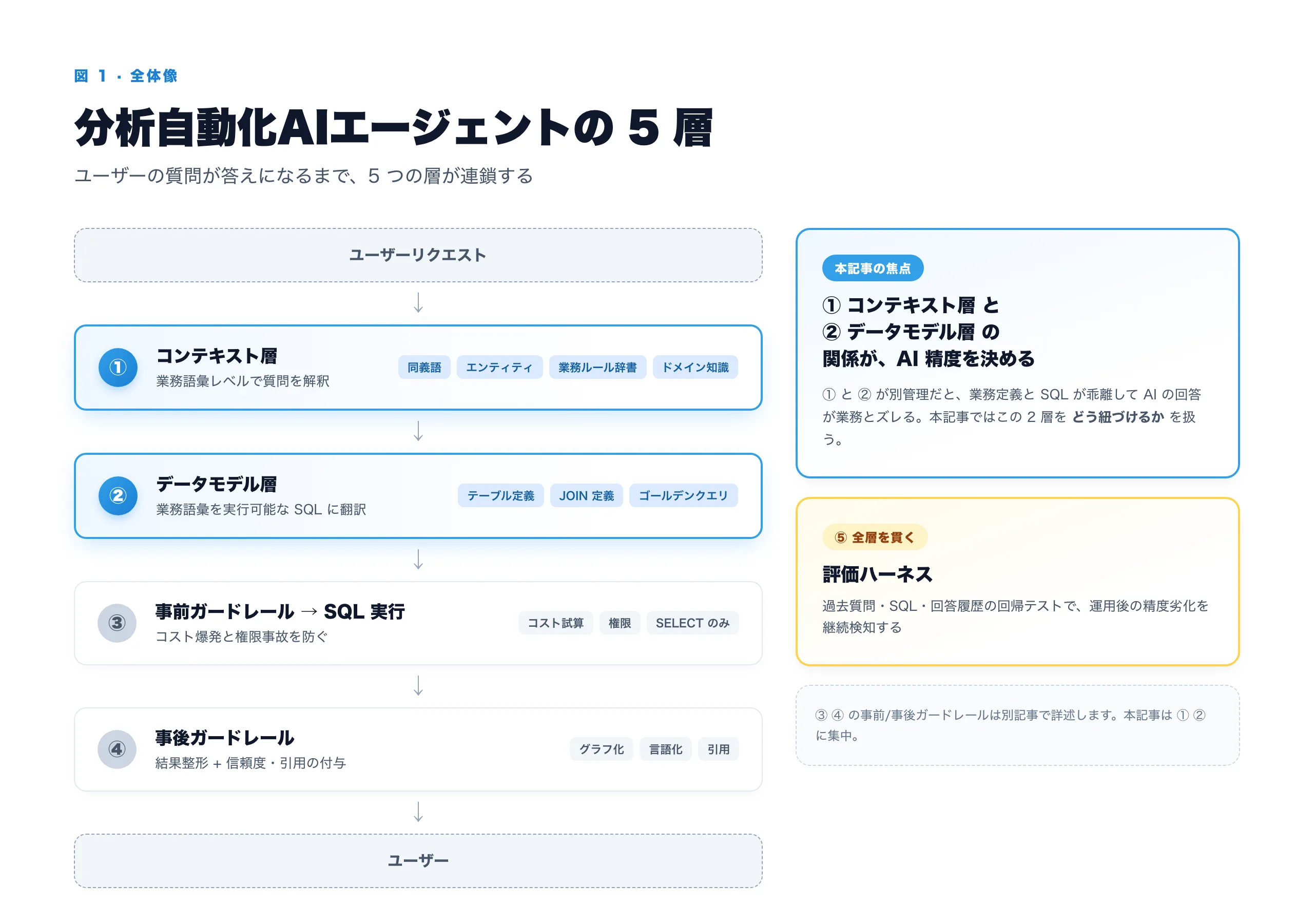
まず、ユーザーが質問してから答えが返るまでの 処理の流れ だけを並べてみます。
[ユーザーリクエスト] ↓ [意図分類 & 業務語彙レベルの分析要件] ↓ [text-to-SQL] ↓ [SQL 実行&結果] ↓ [ユーザー]
各矢印は、何かしらの仕組みを介して次のステップに進んでいます。矢印ごとに「何が必要か」を順に見ていきます。
① ユーザー質問を業務語彙で解釈する層 — コンテキスト層
ユーザーが投げた自然言語を、業務概念のレベルで解釈する段階。「先月のコンバージョン率を出して」という質問に対して、AI はまず「コンバージョン率とは何を指すか」「特定キャンペーンを除外する暗黙ルールはあるか」「組織再編で計算が変わる時期はあるか」などを解釈する必要があります。
このための材料が:
- エンティティ概念(顧客 / 商品 / 注文など)
- リレーション(顧客が商品を注文する、という関係性など)
- 同義語(コンバージョン率 / 成約率 / CV 率は同じなど)
- 業務ルール辞書(特定キャンペーンは除外、テスト注文は除くなど)
- ドメイン知識(四半期末は大口契約集中、組織再編タイミングなど)
これらを総称して コンテキスト層(Context Layer)と呼びます。AI が業務質問を解釈するうえで必要な背景情報・前提条件・業務ルールを渡すための知識層、という意味です。業界では Snowflake / Atlan / a16z などが「Agent Context Layer」という概念で提唱しはじめており、AI 分析エージェントの core layer として認識が広がっています。
② 業務語彙を SQL に翻訳する層 — データモデル層
業務的な解釈ができた後、次は 物理データへの翻訳です。「コンバージョン率」が「fct_orders テーブルの注文数を fct_sessions テーブルのセッション数で割ったもの」と知っているのはこの層。
このための材料が:
- ベーステーブル群(詳細は第一弾記事参照)と ベーステーブル定義(どのテーブルが何を表すか)
- スキーマリファレンス(カラム名・型・PK など)
- JOIN 定義(どのキーで結合するか)
- ゴールデンクエリ(主要分析パターンの SQL テンプレ)
ここが弱いと、AI は SQL の組み立てを間違えます。テーブル選定ミス、JOIN 抜け、フィルタ忘れなど。
③ SQL を検証してから実行する層 — 事前ガードレール
AI が書いた SQL は、実行前にコスト試算 / 権限チェック / 取得系のみ許可、といった検証を経てから実行されます。コスト爆発と権限事故を防ぐ層です。
④ 結果を整形してユーザーへ返す層 — 事後ガードレール
返ってきた実行結果を、グラフ化や言語化(tools)してユーザーに返します。出力には 信頼度 + 参照元(実行 SQL / 参照テーブル / 計算前提)の引用 を必ず添え、ユーザーが「この答えを信じていいか」を自分で判断できる材料を全部出します。
⑤ 全層をまたいで運用を支える — 評価ハーネス
①〜④ は 1 回のリクエスト処理の話。これが運用後も継続して正しく動き続けるかを担保するのが評価ハーネス。過去の質問・SQL・回答履歴を保存し、定期的に同じ質問を AI に再送信して 過去と同じ答えが返るかを継続的に検証することで、LLM のバージョン更新やスキーマ変更による精度劣化を早期検知します。
なぜ Semantic Layer は要らないのか(第 2 弾の論理を整理)
第 2 弾で「Semantic Layer 不要」と書いた論拠を、上のフロー図に対応させて整理し直します。この論は コンテキスト層 + データモデル層が適切に整備されている前提 での話で、3 つの理由から成り立ちます。
理由 1:SL の強み(一貫性)はコンテキスト層 + データモデル層の連携で実現できる
Semantic Layer の最大の強みは「誰が同じ質問をしても、同じ答えが返る」一貫性です。ただ、この一貫性は SL を独立プロダクトとして持たなくても、コンテキスト層 + データモデル層が連携していれば 実現できます。仕組みは 2 段階:
- コンテキスト層が業務語彙を正規化 — 「LTV」「顧客生涯価値」「ライフタイム価値」と人がどう書いても、同義語辞書で同じ正規語にまとめる
- 正規化された業務語彙に紐づく、固定のゴールデンクエリや集計定義が呼び出される — 「LTV」という正規語に対して、データモデル層に登録された決まった SQL テンプレートや集計定義が必ず使われる
この 2 段階のチェーンで、「同じ質問 → 同じ業務語彙 → 同じゴールデンクエリ → 同じ SQL → 同じ結果」が成立します。
理由 2:Semantic Layer はデータモデル層しかカバーしない
これは業界も認めている事実です。Snowflake が提唱する Agent Context Layer の整理を見ると、Semantic Layer は 5 要素のうちの 1 つにすぎません:
"An agent context layer combines five architectural components: a semantic layer, an ontology, operational playbooks, data lineage, and decision memory."
(参照: Snowflake: The Agent Context Layer for Trustworthy Data Agents)
Semantic Layer は「メトリクス定義 + ディメンション + 物理 SQL」までしか持たず、業務オントロジー / 業務ルール辞書 / ドメイン知識(=コンテキスト層)はカバーしません。だから Semantic Layer を入れたとしても、コンテキスト層との繋ぎこみが別途必要になる。
理由 3:Semantic Layer は AI エージェントの自由度を奪う
第 2 弾で書いたとおり、Semantic Layer は 事前定義されたメトリクス × ディメンションの組み合わせ しか答えられません。
✅ 「先月の LTV をチャネル別に」 → 定型、答えられる ❌ 「リピート購入率が落ちた原因を、特定セグメントの行動パターンから探って」 → 想定外、答えられない
経営会議で AI 分析エージェントが本当に欲しい瞬間は、後者の 深掘り分析側です。SL は「想定された質問」しか答えないので、ユーザーは想定外の質問を投げなくなり、結局ダッシュボードと同じ「見るだけ」になります。
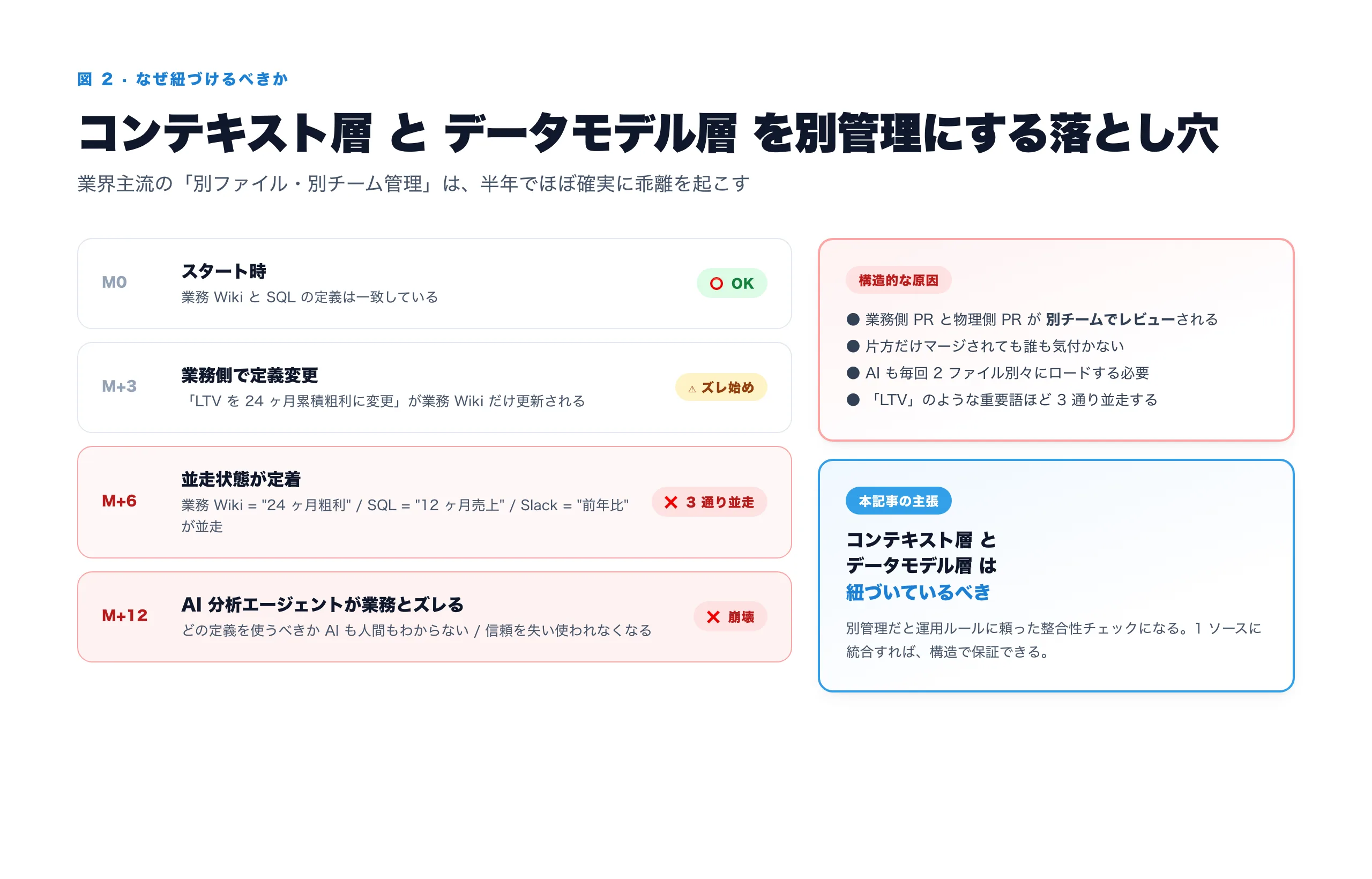
コンテキスト層とデータモデル層は紐づいているべき
私の結論は 「同じソースで 1 つに紐づいているべき」 です。理由は 3 つ。
理由 1:業務定義の変更と物理 SQL の変更は、必ずペアで起きる
「LTV」「コンバージョン率」などの業務定義を変えたら、計算 SQL も変わる。逆に、テーブルのカラム名を変えたら、業務側の説明も追従する。これらは 本来 1 つの変更なのに、別管理にすると 2 つの PR で別々にレビューされ、片方だけマージされる事故が起きる。半年運用すると、業務 Wiki の「LTV = 24 ヶ月累積粗利」と、SQL の「LTV = 12 ヶ月累積売上」が別物として並走している、という典型問題が必ず起きます。
理由 2:AI が両方を同時に参照する
AI 分析エージェントの推論は、コンテキスト層を読んで業務語彙を解釈 → データモデル層を読んで SQL を組む、という 2 段階です。別ソースだと、AI は毎回 2 つのファイルをロードする必要があり、コンテキスト窓を消費する + 認知負荷が高い。1 ソースに統合してあれば、エンティティ単位(例:「案件」を扱う場合)でセマンティック側 + 物理側の両方を一度の参照で取得できる。
理由 3:エンティティとして、両者は同じ Object の異なる側面
「案件(deal)」というエンティティは、業務概念としての側面と、物理データとしての側面(fct_deals テーブル、deal_id を PK とする)の 2 面を持ちます。これは Palantir Foundry が 2017 年から採っている設計思想で、エンティティを 1 つの Object として扱うと、業務概念と物理データを切り離す方が不自然になります。
だから「統合オントロジー」を提唱する
以上の整理から、本記事が提案するのが 統合オントロジー です。
コンテキスト層とデータモデル層を 1 つの YAML ファイルで管理する設計。業務概念(semantic セクション)と物理マッピング(physical セクション)を、エンティティごとに同居させる。
統合オントロジーの中身(あくまで一例として)

統合オントロジーは 1 つの YAML(または複数 YAML を組み合わせたディレクトリ)に トップレベル 4 要素を持ちます — entities(エンティティ + 物理テーブル + プロパティ)、relations(エンティティ間の関係 + JOIN)、metrics(業務指標 + ゴールデンクエリ)、business_rules(暗黙ルールの構造化)。
設計上の核は、entities[] の下に semantic: と physical: を必ずペアで持たせる点。この 2 つは本記事冒頭で説明した 2 層と直接対応します:
- semantic: = コンテキスト層(業務語彙の解釈に使う)
- physical: = データモデル層(SQL の組み立てに使う)
entities:
- id: deal
semantic: # ← 業務語彙の解釈
...
physical: # ← SQL の組み立て
...別ファイルにせず同居させることで、定義変更が必ず同じ PR に乗り、整合性が構造的に担保されます。
主なフィールドの意味
entities[].semantic(コンテキスト層側)
- description — エンティティの業務的な説明
- synonyms — 同義語リスト(「案件」「ディール」「opportunity」を同一視)
- lifecycle — 取りうる状態の遷移(lead → qualified → ... → contract / cancelled)
- seasonal_pattern — 季節要因(四半期末大口集中など)
- organizational_note — 組織変更などの暗黙の前提
entities[].physical(データモデル層側)
- primary_table / primary_key / partition_field — テーブルの基本情報
- table_description — 母集団・更新タイミング・主な用途を平文で記述
- coverage_* / owner — データ品質の状態と責任者
- properties — カラムごとの定義(業務名 / 物理名 / 型 / coverage / 制約 / 説明 / relation 等)
relations[](エンティティ間)
- subject / predicate / object / physical.via / cardinality — エンティティ間の関係 + JOIN 条件 + 多重度
metrics[](業務指標)
- semantic.formula — 業務的な計算式の読み下し
- physical.sql_template — ゴールデンクエリ。AI が SQL を組むときのベース
business_rules[](暗黙ルール)
- sql_filter / affects_metrics — 暗黙ルールの SQL 化と適用先メトリクスの宣言
この構造とフィールドは あくまで一例 で、フィールド名・粒度は事業ドメインに合わせてカスタマイズが必要です(EC なら cart_abandonment_pattern、SaaS なら churn_cohort など、業界固有語彙を semantic 側に足していく)。
統合オントロジーが生む 5 つの効用

- コンテキスト層とデータモデル層の乖離が構造的に起きない(本記事の核となる価値) — 1 ファイル同居なので、別管理で必ず発生する「業務 Wiki と SQL の定義が並走する」「物理側のカラム名変更時に業務側説明が追従漏れする」「AI が両層を別ファイルから読んで参照不整合を起こす」といった事故が物理的に起こせなくなる
- 業務ルール辞書が複数メトリクスで再利用される — exclude_test_deals を 1 度書けば紐づく全メトリクスに自動適用、「テスト案件除外を 5 つの SQL に同期する」という運用作業が消える
- ユーザーの実表現がそのまま辞書になる — 質問ログで投げられた表現を synonyms に足すだけで、組織の業務語彙が 1 ファイルに累積していく
- 属人性排除 + オンボーディング短縮 — 担当者の頭の中にあった業務定義・暗黙ルール・物理マッピングが 1 ファイルに集約、新規メンバーは 1 ファイル読めば全体像を掴める
- Semantic Layer ベンダーが要らない — semantic の同義語正規化と physical のゴールデンクエリの連携で、SL の強みである一貫性(同じ質問 → 同じ答え)を統合オントロジー内で再現できる。独立した SL プロダクトのライセンス費とベンダーロックインを避けられる
業務オントロジーと物理スキーマを 別管理にすると、「LTV」「コンバージョン率」などの業務定義と SQL 計算式が半年でズレ始めて、組織内に 3 通り並走する問題が必ず起きます。1 ファイルにすると、構造で整合性が保証される。これが統合オントロジーの本質的な価値です。
まとめ
本記事で整理した流れは、シンプルです。
- 分析自動化 AI エージェントには 5 つの層が必要(コンテキスト層 / データモデル層 / 事前ガードレール / 事後ガードレール / 評価ハーネス)
- Semantic Layer はそのうち「データモデル層」しかカバーしない — コンテキスト層は別で持つ必要があると業界も認めている
- コンテキスト層とデータモデル層は紐づいているべき — 業務定義変更と物理 SQL 変更は本来ペアで、AI も両方を同時に参照する
- だから統合オントロジー — コンテキスト層とデータモデル層を 1 つの YAML に同居させれば、独立した Semantic Layer は要らない
「LTV」「コンバージョン率」などの定義が組織内で 3 通り並走している状態で AI 分析エージェントを入れて精度を期待するのは無理です。先にコンテキスト層とデータモデル層を 1 ソースで紐づけて管理する、それが本筋。Semantic Layer は要らない、ではなくて、統合オントロジーがあれば Semantic Layer は不要、というのが正確な言い方でした。